人型機器人之窗:從視覺模型剖析人型機器人進展
摘要
現階段人型機器人模型發展重點包含視覺-動作學習模型(VLA)的優化,以及結合多元數據、提升指令解讀與理解人類意圖。在訓練數據方面,主要透過世界模型、人類影片與VR遠端訓練等方式,並更著重「第一人稱視角」,以增強其感知能力。儘管人型機器人的最終目標是實現通用性,但現階段模型發展仍面臨諸多挑戰,使歐美與中國廠商各自發展出不同的路徑。
一. 視覺模型為機器人感知核心
二. 人型機器人模型廠商布局動態
三. 拓墣觀點
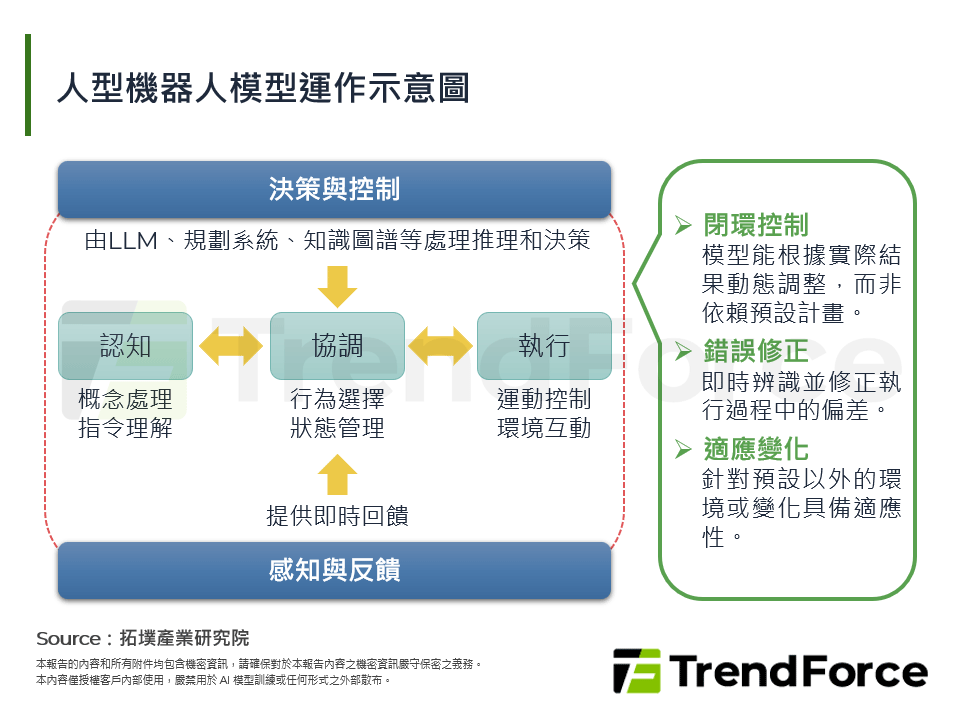
圖一 人型機器人模型運作示意圖
圖二 人型機器人訓練資料說明
圖三 Apple HAT模型說明
圖四 ViLLA架構說明
表一 第一人稱視角和第三人稱視角算法比較
表二 第一人稱資料集舉要